Following on from our brief overview in the last post, we will focus this post on the data exploration and transformation stages of the data science process. We are deliberately constraining the scope of this article to data exploration and transformation in Automated Analytics, to keep the discussion concise and comprehensible. Rather than simply presenting a tool comparison, this post focuses on the data science process itself, which is not often discussed.
DATA SCIENCE PROCESS WITH SAP PREDICTIVE ANALYTICS
The data science workflow with SAP Predictive Analytics (SAP PA) is somewhat different from a typical workflow as outlined in the previous post. The interface of Automated Analytics lends itself more to immediate data processing and transformation for defined analytical tasks rather than exploration; whereas in a data science tool like RStudio, the data scientist may work in more of a sandbox-style iterative approach, visualising different aspects of the data, experimenting with merging the data in different ways and quickly prototyping models to assess the predictive power of the dataset or the viability of the proposed scenario. We will discuss this more towards the end of the post.
The Automated Analytics workflow would typically begin with the Data Manager, where the data set is prepared and transformed for modelling. There is a specific conceptual framework that the tool uses to structure the data, and we are detailing it here because it is very different to anything found in a typical data science workflow; more specifically, a typical data science workflow doesn’t actually impose any such constraints on the conceptual framework. What can be said in favour of the Data Manager here is that it doesprovide a ready-made framework for the user to employ, which may be handy if the user would not otherwise know where to start. However, the user will still need to have some training (or much reading of documentation and tutorials) before they can understand this framework, and an experienced data scientist will probably prefer to work without any impositions on what they can do to the data. The following table describes the specific objects involved in the Automated Analytics workflow:
| Aspect | Description |
|---|---|
| Entity | The object of interest in the problem, the instances of which we wish to make predictions for. E.g. a master customer table. |
| Time-stamped Population | A specific subset of the set of entities defined with respect to a point in time. This is particularly useful when the dataset involves transactional/event-like data. The timestamped population also defines filters, target variables, and sub-sampling for A/B testing and uplift modelling. |
| Analytical Record | An analytical record is where the majority of the work will be done, in particular feature engineering to find useful predictors in the data. This can involve merging tables together and creating new aggregates. |
With the above concepts defined, the Automated Analytics workflow involves the following major steps.
- Defining the entity (i.e. object of interest)
- Performing transformations to engineer useful features with predictive power
- Joining Tables
- Aggregating
Below we will outline some of the key transformations involved in the chosen scenario, with a comparison between a typical process and Automated Analytics. The AdventureWorksdata set contains 68 interconnected tables relating to customers, sales, production, etc. We will work with just a small subset of these tables and the entity model is available below.
JOINING TWO TABLES
The transformation is a straightforward operation, joining the Customer entity as defined by the field CustomerID in the Sales.Customer table with the customer demographics view Sales.vPersonDemographics. The user needs to understand the relationships between these tables; in particular, the fact that the tables join on Sales.Customer/PersonID → Sales.vPersonDemographics/BusinessEntityID.
An important point of comparison between these different workflow styles is illustrated below, for a simple join between the customer table and the demographics table. In a visual interface such as the Data Manager, there are many buttons, drop downs and windows that need to be visited to achieve the operation.
In contrast, when working in R, the entire operation can be achieved in 3 lines, shown below.
df_customer <- sqlQuery(con, 'SELECT * FROM "ADVENTUREWORKS"."vSALES_CUSTOMER"') df_demographics <- sqlQuery(con, 'SELECT * FROM "ADVENTUREWORKS"."SALES_VPERSONDEMOGRAPHICS"') merge(df_customer, df_demographics, by.x='PersonID', by.y='BusinessEntityID')
The operation is similarly concise in SQL.
SELECT * FROM "ADVENTUREWORKS"."vSALES_CUSTOMER" AS c INNER JOIN "ADVENTUREWORKS"."SALES_VPERSONDEMOGRAPHICS" AS pd ON c.PersonID=pd.BusinessEntityID
In practice, a data scientist might first explore and prototype in R, and if the idea looks promising, would create a view in the database so that the operation is available on an ongoing basis for further modelling. Using the Data Manager is somewhat cumbersome, although it does not require an experienced data scientist with programming skills. With some training and knowledge of the data structure/entity relationships, an analyst would be able to achieve this kind of joining operation and more using the Data Manager. Users who have no programming skills might prefer getting acquainted with the Data Manager than learning programming. We should acknowledge here that the Expert Analytics component of SAP PA (that we are not considering in this post) does have some good exploration and visualisation capabilities through its integration with SAP Lumira, which could make it a good starting point for a non-data scientist.
AGGREGATING DATA
Besides joining tables, aggregations will be an essential transformation on the data. Typically, a dataset will contain a great deal of data, such as transactions or sales, that are not so informative individually but can have predictive power through aggregations such as summing, averaging, or counting (among many others). In this case, we will examine how to implement a simple aggregation that indicates a customer’s recent spending.
For a data scientist used to using tools such as R, the approach required for aggregations in the Data Manager can initially feel somewhat foreign. It is not obvious without a little training or reading tutorials and documentation what is required to achieve an aggregation. However, after a couple of successful attempts, we will admit that the interface is good, as long as the provided aggregation functions are sufficient. In the present scenario, we simply wish to sum a customer’s recent spending, and the Data Manager can indeed do this.
The only requirement is that the data to be aggregated must be event-like/transactional, in the sense that there is a date or date-time associated with each row of the table being aggregated. There must also be a means to link entities (i.e. customers) against the rows in the table, on a one-to-many basis. The Data Manager has a useful function, which is the “Period Settings” tab, allowing the aggregation to be performed within a specific period, or several successive periods or user-specified durations, relative to the time-stamp defining the time-stamped population. In the example we demonstrate here, we aggregate against Sales.SalesOrderHeader with OrderDate as the event ordering field, and sum TotalDue within two successive periods of 6 months preceding the “present” time. This produces two new features that may have some predictive power in our problem.
The New Aggregation module also lets the user filter data for aggregation and pivot based on categorical variables. This can be very useful, as it will automatically generate new fields for each successive period and pivot. This automates a large amount of work that might otherwise have to be performed from scratch for each new exploration.
However, the successive periods are rigidly defined; the intervals being considered can only be what has been built into the program (integer multiples of Year, Quarter, Month, Week, Day, Hour, Minute, Second). The periods must also be contiguous and non-overlapping. Additionally, the aggregation can only pivot against a single field at a time, and a complex workaround would be required to achieve pivoting against “crossed factors”. This highlights the key point which is that there is a balance between the ease of use of functionality that has been built into the tool’s front end, and the reduced ability to perform highly customised transformations. In some cases, the former may be sufficient, but in other cases an experienced user will prefer to not be constrained, and tools such as RStudio allow infinite flexibility.
A more significant limitation of the Data Manager is that some data structures may not be compatible with the assumptions of the tool. In the AdventureWorks dataset, there are dimension tables and fact tables, which are related by combinations of inner joins and outer joins. In some cases, fields we need for an aggregation may be in distant tables requiring some significant data manipulations and modelling to access. In the next section, we will provide an example of such a transformation.
The key point is that there is a regime where the convenience of the Data Manager, with aggregations against successive periods and pivots, can work, but once the data or the transformation gets a bit more complex, the tool becomes increasingly difficult to use.
JOINING TABLES AND AGGREGATING
This is a more complicated transformation. We wish to create a feature that describes how a customer’s product purchases are weighted within the different product categories. This involves joining several tables together (as depicted in the entity relationship diagram shown earlier). Achieving this feature requires us to count rows in the SalesOrderDetail table for a given customer within each product category. This presents a significant challenge in Automated Analytics. The Data Manager is indeed capable of performing this general class of aggregation, using the provided Count function, but the aggregations can only be performed against a single table or view that already exists in the data backend, whereas in this instance the necessary data is dispersed across several tables. Each individual product purchased corresponds to a single row in Sales.SalesOrderDetail, but the associated product category is accessible only through inner joins to Production.Product and then Production.ProductSubcategory. Furthermore, the original entity table Sales.Customer is only connected to Sales.SalesOrderDetail through outer joins via Sales.SalesOrderHeader. We have not been able to achieve this transformation solely using the Data Manager. Instead, it is necessary to create a new table or view in the Data Manipulation Editor (or otherwise) that will be pushed back up to the database and can then be aggegated against in the Data Manager.
This solution is somewhat non-trivial and involves some out of the box thinking and ingenuity with data structure modelling. In the Data Manipulation Editor, we select the table Sales.SalesOrderDetail as the source, and from here two main steps are necessary. First, we must join to Sales.SalesOrderHeader and then Sales.Customer in order to obtain the CustomerID for each sales item; the CustomerID will serve as the joining key when later performing the aggregation. Second, we must join to Production.Product and then to Production.ProductSubcategory to make available the field ProductCategoryID. We then need to specify that this data manipulation should be saved to the database as either a table or a view. As illustrated in the diagram below, the new data structure provides a means by which to join to the entity table (via CustomerID), an ordering field (OrderDate), the quantity to be aggregated (either by counting rows or summing LineTotal) and the ProductCategoryID against which to pivot.
Returning to Data Manager, we can now aggregate against the new table (or view) we have created, joining on CustomerID, counting rows and pivoting on ProductCategoryID. This gives counts of product category sales per customer, which we need to convert to a normalised weighting by creating a new expression that divides each count by the customer’s total sales. These features are now ready for modelling.
We liked that we had the option to interact with and create new tables in the database, although it would have been more convenient to carry out the transformation within the Data Manager itself, and not be required to push up new views or tables to the database. Although we found it a little difficult to build the transformation in Automated Analytics, we wouldn’t consider this type of transformation to be unreasonable. Undertaking a task outside of what the tool is designed to do can be cumbersome, and we look forward to future releases with this capability included. The equivalent transformation within R or SQL would also be non-trivial, although it could be straightforwardly performed by a competent coder.
DISCUSSION
Data Exploration and Transformation in Automated Analytics
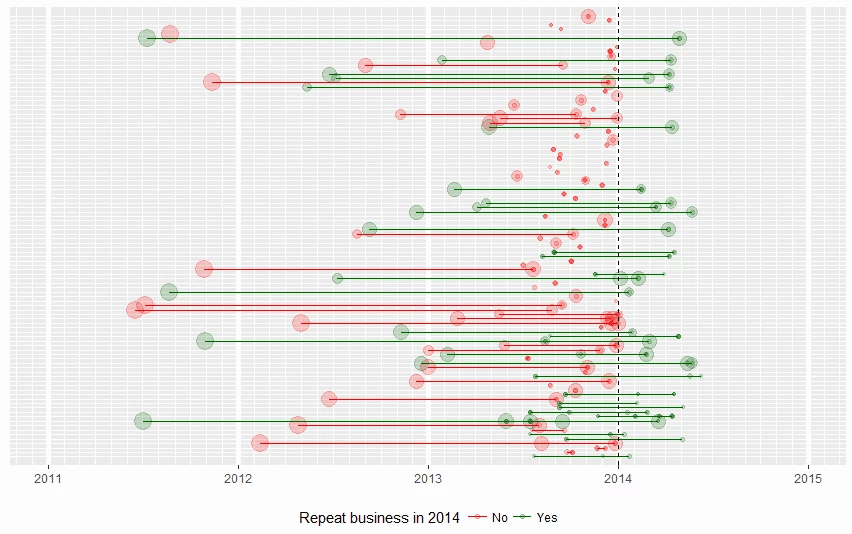
In data science, there is no universally applicable workflow. The promise of Automated Analytics is a guided wizard for carrying out advanced analytics, which we believe to be quite a reasonable proposition, but such a promise will always be limited to a subset of the advanced analytics problem space – if your business falls into one of these subsets then this tool will be beneficial. However, if you’re in the initial stages of exploring newly digitised data and considering derivable value, you’ll need to think more about a data scientific process rather than a specific tool. The first step is always to get the data and start exploring which we’ve always found to essentially be the same step. This is where our data scientists spend most of their time and will typically be quite visually driven; one of R’s strongest features is a powerful inline visualisation functionality. As a case in point, as part of our process in developing this blog post and the AdventureWorks scenario, we produced the following plot in a few lines of R code:
This is a visualisation of customer life cycles and spending habits which helped to develop the problem statement that we would end up using, and this illustrates how important exploration and visualisation are at the start of the data science process.
TRANSFORMATION LIMITATIONS
As we have illustrated earlier for some specific cases, there are some limitations to the kinds of transformations that can be achieved in the SAP tool. The New Aggregate feature does provide aggregations with rolling windows and pivots, but there are limitations if one wishes to go beyond calculating more than the 10 functions offered. Things like calculating the median or mode as a window function are unavailable, and more generally there are no customisable rolling window functions. Building these features can have a tremendous impact on model accuracy. Whilst they could indeed be easily built into the database, that does then require the process to go beyond the confines of the SAP tool, and requires someone with database modelling skills to be involved. Creating and playing around with these kinds of features is part of the iterative process of doing data science on real world problems, and the best tools for the job will be those that let the user work as smoothly as possible, without encountering roadblocks.
AUTOMATING ANALYTICS
You may be wondering what is automated? The answer is the model building process, which we haven’t looked at here, because it is a minor part in the data science process. There was a time when parameters would need to be tuned, data scaled, principal components analysed, different models benchmarked, etc. These days much of this can be abstracted away in analytics tool sets so data scientists can work on the more important feature engineering. This is a relative strong point of Automated Analytics, it leads the user into creating features rather than adjusting the various knobs and dials that can affect model accuracy. We have explored this issue through a realistic scenario and every data scientist knows that’s it’s the killer features that are going to impact model accuracy the most.
Whilst the modelling process is relatively painless, some of the other features of the Data Manager are not straightforward. For example, there is a New Normalization feature aimed at normalising a numerical variable prior to modelling. The Help panel provides some instructions about using the feature but does not really explain what each term means. It would really be necessary to have a thorough tutorial or receive training from an experienced user of the program to have any idea of how to use it.
The way in which data is introduced into the program is counter intuitive for someone coming from mainstream tools such as R and Python. Normally, a data scientist would just obtain data from the database and start working with it directly. The Data Manager does require the user to think in terms of entities, time-stamped populations and analytical records. This is a double-edged sword; while on one hand it provides a ready-made conceptual framework that many problems could fit, it does put constraints on how the user must formulate and solve their problem.
CONCLUSION
The data science process involves obtaining data, cleaning, exploring, visualising, defining the problem statement, and only then can one move on to transforming the data, engineering features and creating models. This process is traditionally performed by data scientists in conjunction with database developers, using the tools they are comfortable with, such as Python/RStudio and relational databases (e.g. any variant of SQL). There are many offerings on the market such as SAP Business Objects Predictive Analytics which claim to make this process, and the associated benefits of predictive modelling, accessible to a wider range of users, who may not have the same training as a data scientist, particularly with respect to programming skills.
We evaluated Automated Analytics by using a realistic scenario constructed on a data set that is typical of most organisations, and at the end of it we have come to some conclusions about the tool.
We found that the process of exploration, visualisation and defining of the problem is easier in a sandbox environment like RStudio. The Data Manager aspect does not offer this as well as it could. The user must proceed to immediately manipulate data directly toward a preconstructed problem. Expert Analytics has some exploration and visualisation capabilities but currently sits off to the side as a distinct and incompatible offering. We will explore this in a future post.
The Data Manager offers a wizard-style GUI interface, with reasonably well-defined areas which can help an end-user to orient themselves and navigate through the program. The wizard-style “room” structure will be friendlier to some users, especially previous users of the KXEN suite or non-programmers. On the other hand, it can be a bit of work clicking through many windows to achieve transformations that a data scientist would achieve in a few lines of code in R or SQL. As always this is a matter of preference; and the process is opened to a non-programmer who may prefer a GUI, but a programmer will appreciate the conciseness of code.
Data Manager has a specific conceptual framework involving entities, time-stamped populations and analytical records that can be handy when the data is pretty much “ready to go”. It is well-suited for event-based data, as it was originally built for the customer-centric Salesforce suite. The built-in functionality of Expression Editor and New Aggregation can make the creation of new features reasonably straightforward, particularly with regards to rolling windows and pivoting against categorical variables. This could be challenging and require repeated manual coding in R or SQL. However, we have identified instances in this post where the required transformations stretched this conceptual framework and required workarounds, or were not possible. For example, the aggregation is limited to the handful of functions provided and to only successive, contiguous periods and nothing more complex, e.g. overlapping rolling windows. The Data Manager and Automated Analytics may be better suited to scenarios where the data is very close to being ready for modelling, requiring perhaps just some simple merges and aggregations. However, when substantial transformations are required, it is better to use other tools first.
Although we wouldn’t consider it a general-purpose tool, SAP Automated Analytics will find a home in those organisations that have a very good idea of the modelling they need to carry out and where involved exploration and visualisation are not necessary.
We recommend Automated Analytics in situations where:
- The problem has been well defined;
- The underlying or complex data transformations exist and are available to Automated Analytics;
- The problem, and associated transformations, match the conceptual framework and/or is formulated to meet the constraints of the tool;
- The user does not wish to learn a programming language.
NEXT STEPS
In the next blog post of this series, we will extend our exploration to also cover the modelling part of the process. SAP Predictive Analytics provides, in addition to Automated Analytics, the Expert Analytics suite, which is aimed at a greater degree of control over the algorithms being employed. We will make a detailed comparison of this tool and the best modelling capabilities available in R.