
Data Science is a rapidly growing discipline as more and more businesses recognise and invest in the role that it plays in digital opportunities and seek to take advantage of the associated benefits. On the one hand the size of this investment is encouraging – on the other hand the failure rate for Data Science projects is alarmingly high! And a statistic like this deserves further analysis.

There are obvious challenges for data science, such as the lack of quality data to work with in the first place. In our experience there are other fundamental issues facing Data Science projects that are not so obvious:
- Data Science is experimental in nature – and this makes executives nervous when investing.
- Data Science is often executed as a technical exercise, without enough focus on how much value the Data Science idea will deliver and whether that value is believable.
- Data Science is tackled inconsistently within many organisations, lacking the appropriate guidelines, templates and accelerators, leading to inconsistent results and prolonged time to outcomes – be that success or failure.
In this article we explore these issues and present the case for organisations to adopt a consistent approach – just like they would for the delivery of any project. The ultimate goal is to see more Data Science projects make it into production and into the hands of users.
Issue 1: The experimental nature of Data Science can make executives nervous
In Data Science the work is experimental until the hypothesis has been proven, and only then can requirements be definitively established for development of the end product. In contrast, for software delivery – regardless of approach – requirements are established upfront based on end-user needs, before the team proceeds to design, build, test and deploy.
Whilst requirements in software delivery can be ambiguous, and unexpected issues can arise along the way, this mode of delivery is what we would term “predictable”. Data Science, on the other hand, is inherently “unpredictable”. The best business nous and domain expertise can feed the ideation process, but when push comes to shove, the data might simply not be there, or the relationship being sought might not actually exist in the data or be buried in noise.
We are asking executives to invest in the unpredictable nature of Data Science
As it is this unpredictable nature that we ask executives to invest in, it is critical to provide confidence that money is not being wasted for the sake of experimentation.
A Data Science methodology also provides consistency in the way Data Science projects are tackled and communicated across an organisation, reducing ambiguity on what success looks like and ensuring lessons are learnt for future endeavours.
We suggest organisations look for two key elements in the way their Data Science teams work.
A consistent process that is appropriate for your organisation’s capability
Where traditional software development typically proceeds sequentially through activities such as design, build and test, the key activities in Data Science are iterative. Overall, the typical Data Science activities described below are well understood, although challenges arise when practitioners execute and traverse these activities inconsistently.
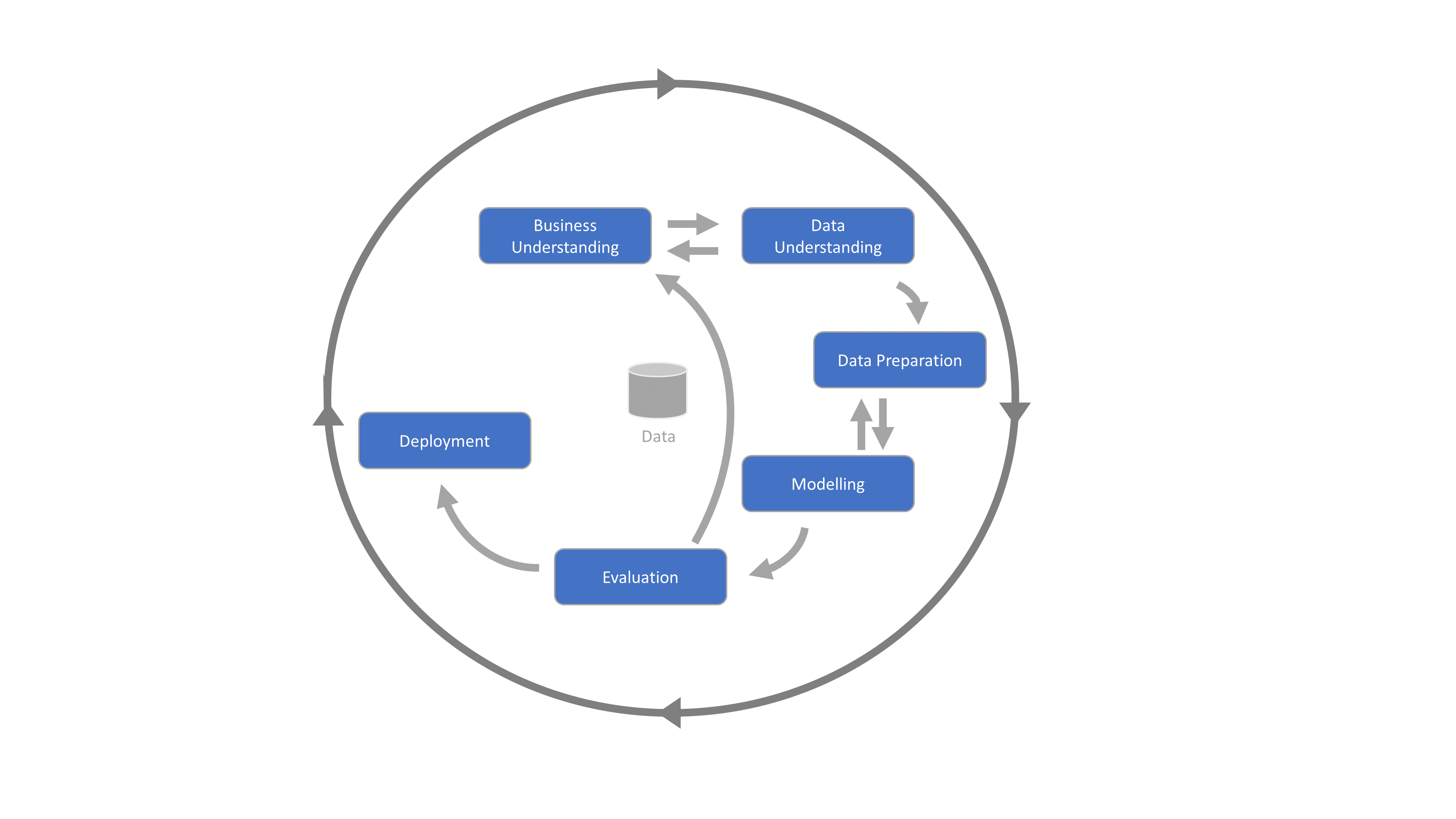
We recommend that organisations look for approaches that are consistent with their organisational capability. For organisations starting out there is no point implementing processes that have a heavy focus on deployment. At the same time, organisations looking to scale their investments, need to avoid the trap of iterating too much.
The right checkpoints and questions to make it clear how to navigate the process
The pathway through the activities listed above will generally be highly iterative and non-linear, which must be anticipated and accounted for. However, it is this iterative nature that presents the creative process of Data Science with its greatest traps – running down rabbit holes to improve accuracy and getting distracted by the interesting data!
The creative process of Data Science presents practitioners with enticing traps
With the need to adapt to findings as they are uncovered, it is critical that there are checkpoints in the process where key questions are asked to gauge progress and decide how to proceed. These questions need to be underpinned by the business objectives and make it clear what actions to take and whether it is worth continuing.
Issue 2: Data Science is often executed as a technical exercise
Data Scientists who are passionate about the data and technology can often neglect the need to focus on articulating the value of the idea and proving that it is believable. This can have the result that either the Data Science team cannot effectively justify and prioritise projects, or that effort is being expended on pushing on with ideas that cannot create sufficient value for the business.
We encourage Data Science teams to focus on three key elements to prove the value.
Quantifying the potential return on investment
Before proceeding to thoroughly test an idea, it is important to do the appropriate analysis to show what return on investment could look like. Engage business stakeholders and review existing metrics to understand the value drivers, in order to quantify the size of the prize that is being chased.
This step becomes vital in preparation for evaluation as it may determine the willingness to pursue a use case further if the potential return is big enough.
Sponsors may well be excited about the promise of Artificial Intelligence, but they will still want convincing on whether an idea is worth pursuing and which ideas are best for the organisation.
Understanding the feasibility of realising value
It is also critical to consider whether the value is viable from two angles:
1. Business process impact
2. Technical landscape
The process change required to implement the idea needs to be explored from the outset to understand who is impacted and who actually benefits. This can be achieved through a process and value mapping activity. It is here where we can also identify whether the current process has some existing performance we are hoping to improve upon, or whether stakeholders can indicate a benchmark accuracy that we can set as a target for the Data Science exercise.
In the simple forecasting example depicted below you can see that improving the demand forecast may have significant benefits for an optimised supply chain but will impact the current process for the sales team. In more complex cases there may be contracts and pre-existing agreements to consider especially in asset rich environments.
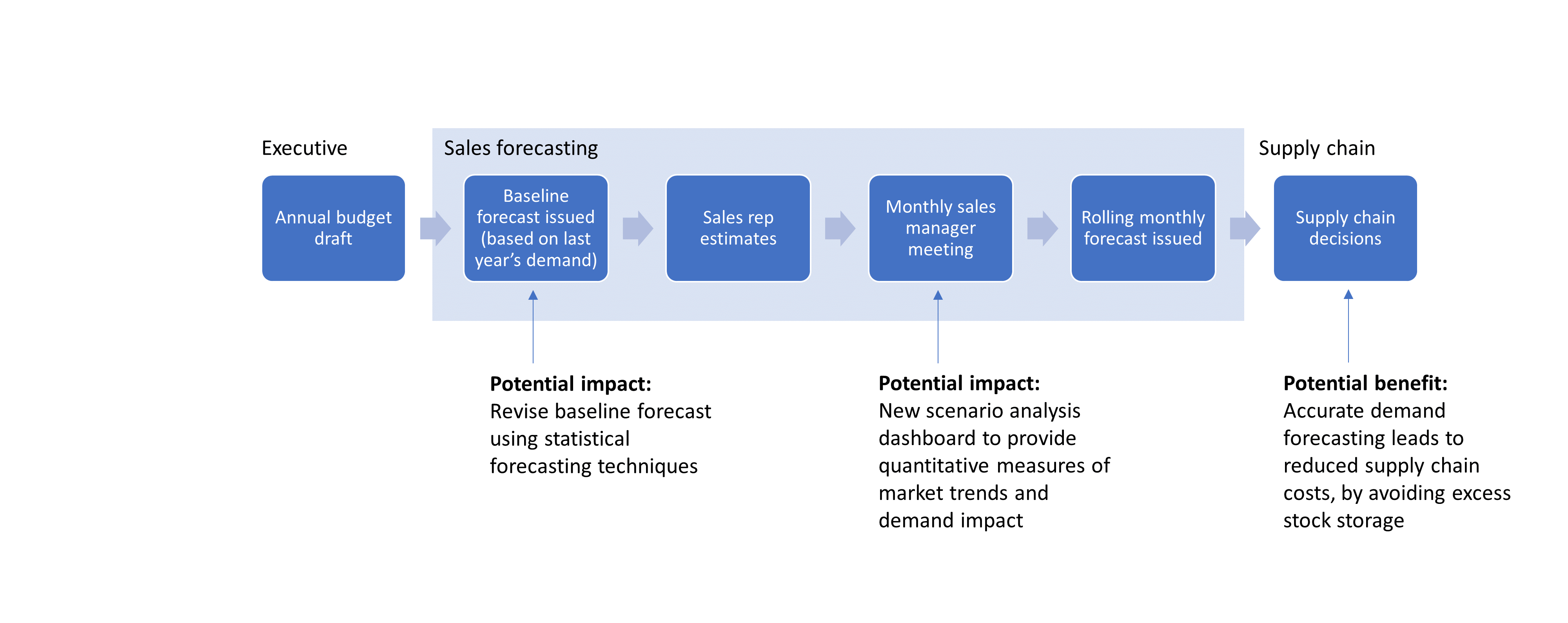
Underestimating or overlooking the process impacts is one of the largest causes for Data Science failing at its primary goal: adoption by end users.
Furthermore, consideration should be given to what form the final data product might take, to ensure that something useful is being put in the hands of users. Is it as simple as an input into a monthly business intelligence report or is it an interactive app for your customers? The potential effort and investment required in your technical landscape should also be thought through as this will impact the potential return.
Evaluate the results not the technical performance
A thorough final evaluation of results ensures that the insights gathered, and the models produced, truly do meet the business objectives and success criteria that were determined initially. It is critical that this is from the business perspective, and not just from a technical standpoint.
Data Science models are never 100% accurate and carry an inherent uncertainty and thereby risk. It is the translation of risk into business terms that is important. High return with low associated risk is nirvana, but seldom reality. A lens of business evaluation makes the potential return believable.
Too often Data Science seems to suffer from an urgency to push the model with the best technical performance through to deployment
Issue 3: Data Science is tackled inconsistently within many organisations
Data Science is a highly technical process, involving the extensive use of tools to work with data, and requiring a great deal of documentation to capture business objectives, hypotheses, data definitions, modelling results, etc.
With many organisations building Data Science capability organically, usually through practitioners who themselves are new to the corporate environment, data scientists can fall into the trap of not making best use of available tools to efficiently execute this process, potentially reworking the same tasks again and again.
Furthermore, they may not be achieving a consistent quality of deliverables across their projects if they are not standardising the artefacts and guidelines that support the creative process.
This is where having the right accelerators going into a Data Science initiative can significantly reduce time to outcome, give the team more focus on higher value activities, and improve the consistency of output across the organisation.
When these accelerators “talk business language” and help data scientists communicate results back to business stakeholders, they are even more valuable.
How many of your Data Science projects are making it into production? Are you happy with this number?
This question applies to all stakeholders, be they the sponsors who are investing, the leaders who have to justify the investment or the passionate data scientists who want to see the results of their effort being used out in the business.
For those who are not satisfied we encourage a review of your Data Science practices to see if the issues above resonate. If they do – consider adopting a methodology or reviewing the methodologies you are currently using. For an independent review of your Data Science projects contact us.
In Part 2 of this series ‘How complete are existing Data Science methodologies?‘, we explore some existing methodologies in the data science discipline to understand how they help in addressing the key issues raised in this article.