
Enterprise back ends are typically a dry subject. Not for me! That’s why I jumped at the challenge to pair a bleeding edge machine learning framework with a tried and trusted corporate system.
SAP is one of the biggest software company you have never heard of. 76% of all worldwide business transactions touch their systems; you know when you direct debit money into a friends account, and it magically shows up – or you receive a bill from your local utility, or buy a song on Itunes? There is a very robust, predictable and boring infrastructure that underlies these processes, that no-one notices unless it stops working. SAP have made it their business to specialise in these systems.
A large chunk of the world’s data goes through these systems, and understanding their analytical potential should be a priority for any SAP-based organisation. In this article, I will very briefly discuss the two systems, and look at how they can be used in a data science context. More specifically, when h2o ought to be used as your machine learning engine based on the size of your data.
HANA
SAP have been rolling out their in-memory HANA database for a number of years, and will continue to do so for many more. This is or will be the backbone for many SAP businesses in the years to come. The good thing about HANA from an analytical perspective is that it offers a full blown SQL interface to the data, which resides in RAM. Although this solution only scales as far as the company wallet, it is typically big enough to deal with objects that are less than 100GB. For many traditional organisations, this is far larger than most of their data sets. The SQL interface means that we can carry out complex data transformations, or more importantly, the data transformations carried out by a data scientist can be easily carried out by a HANA developer to feed into a machine learning model.
h2o
h2o is a machine learning engine that I have been playing with for a couple of years now. Like a lot of start-ups, it is narrow in specific product capability, has world class performance, very easy to use, and platform agnostic. Regression, classification and clustering are the capabilities; scalability, performance and ease-of-use are the features. It is finally starting to get the recognition that befits it, this year debuting in various analytics product infographs here and here.
Why the pairing?
At first glance they may look like strange bedfellows, but having used both systems extensively, it seems to me there is an ‘analytics gap’ in HANA’s capability. It sits somewhere between 1GB and 50GB data sets. Below this you have HANA PAL/R server, and above this you have Vora (Hadoop for HANA). I suspect many traditional organisations have most of their datasets within this range, or less. I think h2o is a great option for those companies that can’t yet justify a Hadoop investment, but want to leverage their HANA hardware where many of the policies, processes and procedures for running analytics workloads already exist.
A large chunk of the world’s data goes through SAP systems, understanding its analytical potential should be a priority for any SAP based organisation
Why train h2o models from HANA server?
Some of you may be thinking whether or not it’s important to be able to remotely train a model from a HANA environment. My perspective in this article is from a traditional SAP corporate, this involves model management, scheduling, backup & redundancy, security, etc. These aspects aren’t too important to a data scientist competing in a Kaggle competition. In an SAP corporate environment there are people whose job it is to implement and maintain these policies and processes. Positioning h2o as bolt-on technology allows it to more easily integrate into the enterprise environment.
The data set
I chose the well known airline delay dataset which I’ve used over the years for various benchmarks, and am quite familiar with. It records sundry details of US airline flights from 1987 to 2008. My goal was to train a model to predict how late (or early) an incoming flight would be. A regression model like this is fairly straight forward, I’m not too interested in accuracy at the moment, rather the process.
After various transformations and culling, I was left with a ~5GB data set. I then carried out some basic data transforms like squaring the flight distance to emphasise the effect of long duration flights. I also did some slightly more complex feature engineering; I summed the number of departures for a given airport each day, the thinking being that a busy airport may be more prone to delays. On the other hand some airports are bigger, and are therefore technically more ‘busy’ under the rule I created. So ‘busy’ is a relative term depending on the size of the airport.
Let’s create a new feature; the difference between the median number of daily departures per airport, and scheduled number of departures. So if an airport is expecting a larger than usual number of flights, this will be accounted for by this value, and vice-versa. Constructing killer features is the best way to increase the accuracy of a model. This takes creativity, curiosity and familiarity with the data.
And this is one of the reasons why data scientists won’t be replaced by robots any time soon.
Constructing killer features is the best way to increase the accuracy of a model, this takes creativity, curiosity and familiarity with the data.
HANA has a full blown SQL environment for transforming data. That is one of the reason I was interested in pairing it with one of the increasing number of machine learning engines. Much of what a data scientists does is not modelling, it’s pulling together various data sets from multiple non-compatible, undocumented and non-normalised data sources. This is especially the case in traditional businesses, which really are most businesses.
I should mention that I ran my transformations and modelling on a subset of data on a local machine with my favouRite language. When I was satisfied with my data structure as a model input, I worked with one of our SAP devs to implement this transformation on the HANA database. This is not because HANA is particularly difficult to use, rather a sensible approach to analytics problems with real-world systems. Stitching together thousands of SAP tables is not an appropriate use of a data scientists time, so we like to pair up appropriate skill sets; a unicorn data scientist I am not.
Performance
We employed h2o’s gradient boosting machine algorithm. Like all of h2o machine learning algorithms, not only does it parallelise across processors, it also distributes across machines. Beginning with 20 million records, we incrementally added 20 million records and recorded both the h2o modelling time consumed, and the total procedure time as reported by HANA. We plotted them in order to understand where, if any bottlenecks occur.
For our scenario we ran the HANA database and h2o on AWS ec2 instances.
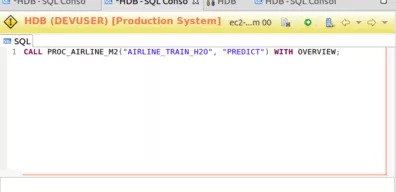
The procedure call from HANA can be treated like any other procedure in HANA. The output can be a table that feeds a campaign (for marketing data), or determines some action.
Representation of the setup for our scenario

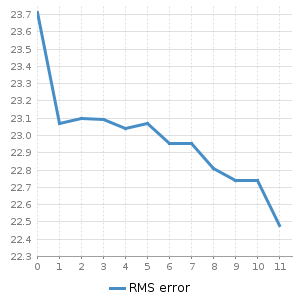


At lower record counts, this is more of an h2o compute bound process. As the record count grows we see the bottle neck shifts to other processes associated with the pipeline. However, it is not associated with shifting data across systems, having repeated the process locally, I can confirm that this is on account of the h2o object conversion process I implemented, admittedly I could have done this better; perhaps fodder for a future blog 😉.
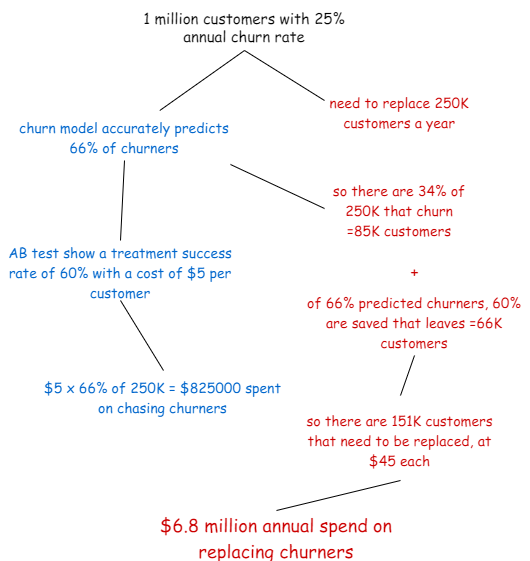
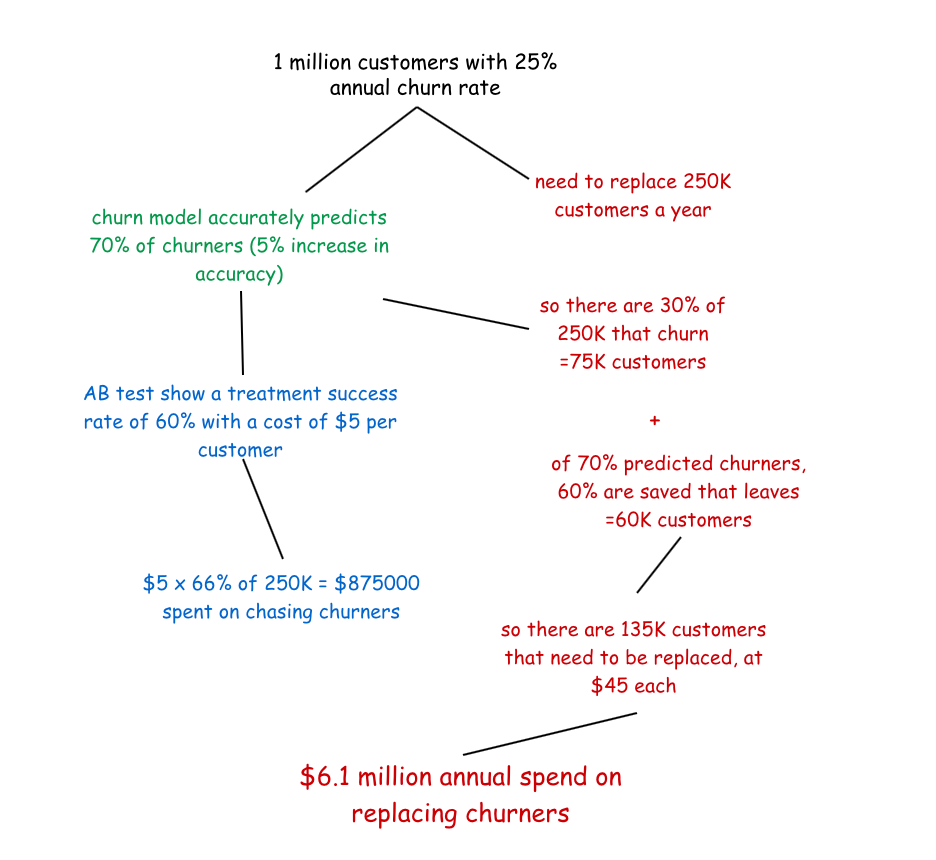
So let’s look at this in perspective, say your company has around a million customers paying bills to you each month, and you wanted to predict who was going to pay their bill late. Now you might want to rebuild this model every month (or week) to adjust for market conditions, new product offerings and prices, etc. So with 12 months of data for a million customers you’d be looking at 120 million rows, and with a dozen or so features, you can be confident of knocking it over within half an hour with a modest AWS setup.
Although there are a few things I’d still like to look at.
- I believe in this case, a compute optimised ec2 machine would have been advantageous in hastening h2o run time.
- I neglected h2o’s JDBC connectors this time, and rerunning the benchmarks with this included would be of interest.
Additionally, we have not discussed frameworks for securing and enterprising these processors. You can come up with the best model in the world, but if it doesn’t fit into a corporate tech paradigm, you’ll be running it on your laptop, again.
Conclusion
We looked at how a third party product like h2o can complement an SAP HANA corporate environment for carrying out machine learning workloads – lifting compute from our operational datastore and over to some relatively cheap AWS kit. During this investigation, we
- called h2o from a HANA client, and
- transferred data and carried out a typical machine learning job
- retrieved the results back into HANA environment
Proving out this capability with this relatively modest task means we can incorporate it into existing analytical processes associated with HANA. Although some work still is needed around optimising the pipeline, there is great potential in bringing products like this together, and in doing so help to bring bleeding edge capability to staid and solid enterprise systems.
Learn more about h2o.ai.